2023년 5월 3일 232p~261p
5.1 복잡도
복잡도는 시간 복잡도와 공간복잡도로 나뉜다.
빅오 표기법 : 시간 복잡도

시간 복잡도란 문제를 해결하는 데 사용한 알고리즘의 로직이 얼마나 오랜 시간이 걸리는지를 나타내는데 쓰이며 보통 빅오 표기법으로 나타낸다.
예를 들어 입력 크기 n의 모든 입력에 대한 알고리즘에 필요한 시간이 10n^2 + n 이라고 하면 다음과 같은 코드를 상상할 수 있다.
for(let i=0;i<10;i++){
for(let j=0;j<n;j++){
for(let k=0;k<n;k++){
if(true) console.log(k);
}
}
}빅오 표기법이란 입력 범위 n을 기준으로 해서 로직이 몇 번 반복되는지 나타내는 것인데, 위 코드의 시간 복잡도를 빅오 표기법으로 나타내면 O(n^2)이 된다. 즉, 가장 영향을 많이 끼치는 항의 상수 인자를 빼고 나머지 항을 없앤 것이다.
위의 그림처럼 O(1)과 O(n)은 입력크기가 커질수록 많은 차이가 난다. O(n^2)는 이미 n이 1이후로 급격한 차이를 보여준다.
따라서 O(n^2) 보다는 O(n), O(n)보다는 O(1)이 되도록 로직을 작성하자.
공간 복잡도
공간 복잡도는 프로그램을 실행시켰을 때 필요로 하는 자원 공간의 양을 말한다. 정적변수로 선언된 것 말고도 동적으로 재귀적인 함수로 인해 공간을 계속해서 필요로 할 경우도 포함된다.
5.2 선형 자료 구조
5.2.1 연결 리스트
연결 리스트는 데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화시킨 자료 구조다. 삽입과 삭제가 O(1)이 걸리며 탐색에는 O(n)이 걸린다.
prev 포인터와 next 포인터로 앞과 뒤의 노드를 연결시킨 것이 연결리스트이다.
- 싱글 연결 리스트 : next 포인터만 가짐
- 이중 연결 리스트 : next 포인터와 prev 포인터를 가짐
- 원형 이중 연결 리스트 : 이중 연결 리스트와 같지만 마지막 노드의 next 포인터가 헤드 노드를 가리킴
장점
- 새로운 elements를 삽입, 삭제 시 용이
- restructuring이 덜 복잡함
단점
- array보다 많은 메모리 사용
- 특정 element를 검색시 비효율적임(처음부터 하나하나 다 검사해야해서)
자바스크립트로 연결 리스트 구현하기)
자바스크립트로 연결 리스트를 구현한 코드를 보면 연결 리스트와 더 친해질 수 있다:)
Javascript를 이용한 Linked List 구현
Javascript에서 연결리스트는 객체를 통해 구현할 수 있다.아래 예시는 두개의 객체를 next로 연결하여 Linked List의 기본적인 구조를 보여준다연결리스트의 핵심은 node이며, node는 data를 담는 data field
velog.io
5.2.2 배열
같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합이다. 중복을 허용하고 순서가 있다. 탐색에 O(1)이 되어 랜덤 접근이 가능하고, 삽입과 삭제에는 O(n)이 걸린다.
따라서 데이터 추가와 삭제를 많이 하는 것은 연결 리스트, 탐색을 많이 하는 것은 Array로 하는 것이 좋다.
- 랜덤 접근 : 임의의 인덱스에 해당하는 데이터 접근 방식이며 시간 복잡도는 O(1)이다.
- 순차적 접근 : 데이터를 저장된 순서대로 검색하는 접근 방식이며 시간 복잡도는 O(n)이다.
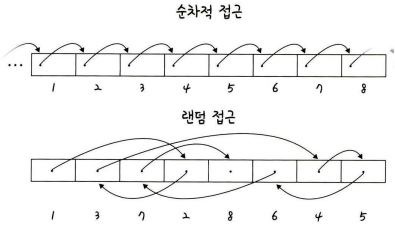
Array의 가장 큰 특징은 순차적으로 데이터를 저장한다는 점이다.
Array를 적용시키면 좋은 예로 주식 차트가 있다.
주식 차트에 대한 데이터는 요소가 중간에 새롭게 추가되거나 삭제되는 정보가 아니며, 날짜별로 주식 가격이 차례대로 저장되어야 하는 데이터이다. 즉, 순서가 굉장히 중요한 데이터이므로 Array 같이 순서를 보장해주는 자료구조를 사용하는 것이 좋다.
Array를 사용하지 않고 순서가 없는 자료 구조를 사용하는 경우에는 날짜별 주식 가격을 확인하기 어려우며 매번 전체 자료를 읽어 들이고 비교해야 하는 번거로움이 발생한다.
* Array와 ArrayList의 차이?
Array는 크기가 고정적이고, ArrayList는 크기가 가변적이다.
Array는 초기화 시 메모리에 할당되어 ArrayList보다 속도가 빠르고, ArrayList는 데이터 추가 및 삭제 시 메모리를 재할당하기 때문에 속도가 Array보다 느리다.
# 배열 vs 연결리스트
배열은 상자를 순서대로 나열한 데이터 구조이며 몇 번째 상자인지만 알면 해당 상자의 요소를 끄집어낼 수 있다. 연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조이며 상자 안의 요소를 알기 위해 하나씩 상자 내부를 확인해봐야 한다.
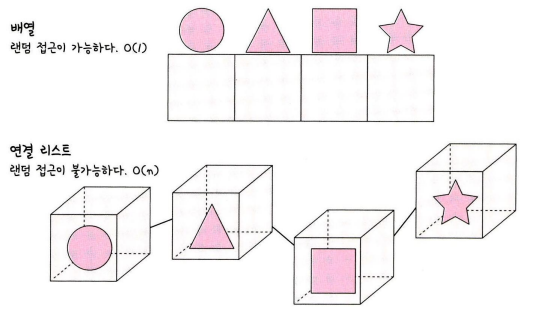
연결 리스트는 랜덤 접근이 불가능하고, 배열은 랜덤 접근이 가능하다.
배열은 그저 상자 위의 요소를 탐색하면 되는 반면에, 연결 리스트는 연결선을 기반으로 상자들을 하나하나 다 열어봐야 하기 때문이다.
배열는 인덱스(index)로 해당 원소(element)에 접근할 수 있어, 찾고자 하는 원소의 인덱스 값을 알고 있으면 O(1)에 해당 원소로 접근하여 RandomAccess가 가능해 속도가 빠르다. 하지만 연결 리스트는 원하는 위치에 한 번에 접근할 수 없다는 단점이 있어, 원하는 위치에 삽입을 하고자 하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 한다.
탐색은 배열이 빠르고, 데이터의 추가 및 삭제는 연결 리스트가 더 빠르다.
배열은 모든 상자들을 앞으로 옮겨야만 데이터의 추가가 가능하지만, 연결 리스트는 연결선을 바꿔주는 것만으로도 데이터의 추가 및 삭제가 가능하기 때문이다.
연결 리스트의 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있기 때문에 이 부분만 다른 값으로 바꿔주면 삽입과 삭제를 O(1)로 해결할 수 있다. 하지만 배열에서는 삽입 또는 삭제의 과정에서 각 원소들을 shift 해줘야 하는 비용이 생겨 이 경우 시간 복잡도가 O(n)이 된다는 단점이 있다.
Array는 검색이 빠르지만, 삽입, 삭제가 느리다.
LinkedList는 삽입, 삭제가 빠르지만, 검색이 느리다.
5.2.3 벡터
벡터는 동적으로 요소를 할당할 수 있는 동적 배열이다. 컴파일 시점에 개수를 모른다면 벡터를 써야 한다. 중복을 허용하고 순서가 있고 랜덤 접근이 가능하다. 탐색과 맨 뒤의 요소를 삭제하거나 삽입하는데 O(1)이 걸리며 맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는 데 O(n)이 걸린다.
참고로 c++ 기준, 뒤에서부터 삽입하는 push_back()의 경우 O(1)의 시간이 걸린다.
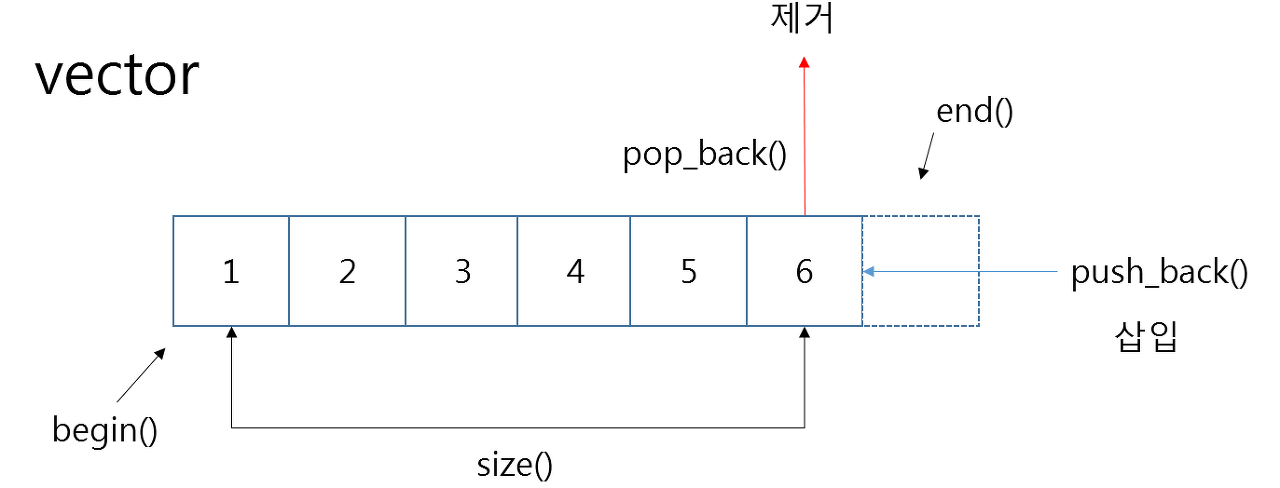
5.2.4 스택 & 큐
Stack과 Queue는 선형 자료구조의 일종이며, Array와 LinkedList로 구현할 수 있다.
Stack은 후입선출(LIFO)방식 즉, 나중에 들어간 원소가 먼저 나오는 구조이고, Queue는 선입선출(FIFO)방식 즉, 먼저 들어간 원소가 먼저 나오는 구조를 갖는다.
스택은 재귀적인 함수, 웹 브라우저 방문 등에 쓰인다. 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다.
큐는 CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행렬, 너비 우선 탐색, 캐시 등에 쓰인다. 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다.
Stack - Stack 메모리 영역
지역변수와 파라미터 데이터 값이 저장되는 공간이며, 메소드 호출시 메모리에 할당되고 종료되면 메모리가 해제되며,
LIFO(Last In First Out)구조를 가진다.
Queue - OS의 스케쥴러
자원의 할당과 회수를 하는 스케쥴러 역할을 할 수 있다.
메모리에 적재된 다수의 프로세스 중 어떤 프로세스에게 자원을 할당할 것인가 그 순서를 결정하는 것이 자원의 효율적인 사용에 있고, 가장 단순한 형태의 스케쥴링 정책이 선입선처리(First Com First Served) 즉, 큐라고 볼 수 있다.
5.3 비선형 자료 구조
일렬로 나열하지 않고 자료 순서나 관계가 복잡한 구조를 말하며, 일반적으로 트리나 그래프를 말한다.
5.3.1 그래프
그래프는 정점과 간선으로 이루어진 자료 구조를 말한다.
어떠한 곳에서 어떠한 곳으로 무언가를 통해 간다고 했을 때, 어떠한 곳은 정점이 되고 무언가는 간선이 된다.
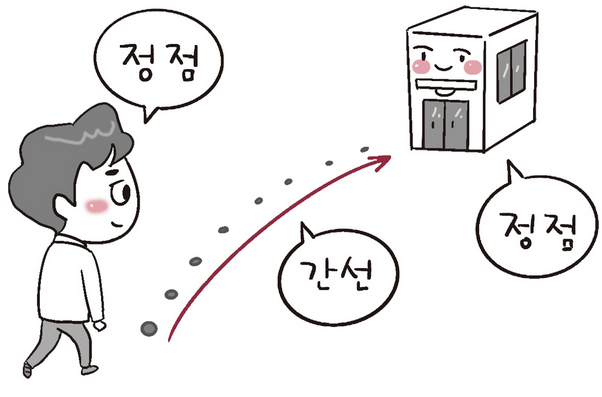
이때 두 정점 간에 한 쪽으로만 방향성을 가진 간선을 '단방향 간선'이라고 하며, 두 정점 간에 양 쪽으로 방향성을 가진
간선을 '양방향 간선'이라고 한다. 그래프는 이러한 성질들을 가지고 다음과 같은 모습을 나타낸다.
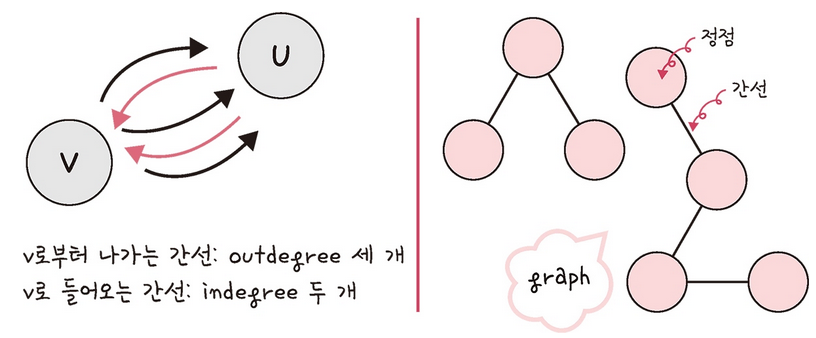
정점으로 나가는 간선을 해당 정점의 outdegree라고 하며, 들어오는 간선을 해당 정점의 indegree라고 한다.
위 그림의 정점 V는 outdegree 3개, indegree 2개인 상태이다.
또한 정점은 약자로 V 또는 U라고 하며, 보통 어떤 정점으로부터 시작해서 어떤 정점가지 간다를 "U에서부터 V로 간다." 라고 표현한다.
* 가중치
간선과 정점 사이에 드는 비용을 뜻한다. 1번 노드와 2번 노드까지 가는 비용이 한 칸이라면 1번 노드에서 2번 노드까지의 가중치는
한 칸이다.
예를 들어, U에서 V로 가는 데 걸리는 택시비가 13,000원이라면 가중치는 13,000원이다.
5.3.2 트리
트리는 그래프의 특수한 형태 중 하나로, 그래프의 특징처럼 정점과 간선을 가지고 트리 구조로 배열된 일종의 계층적 데이터의 집합이다.
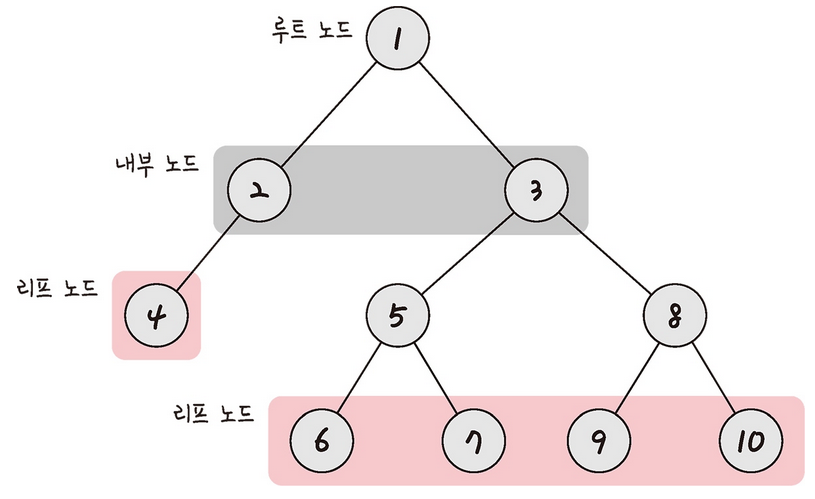
트리는 그래프의 일종이며, 다음 특징을 가진다는 점이 다르다.
- 부모, 자식 계층 구조를 가진다.
- 'V - 1 = E'라는 특징이 있다. 간선 수는 '노드 수 - 1'이다.
- 임의의 두 노드 사이의 경로는 반드시 단 하나만 존재한다. 즉, 트리 내의 어떤 노드와 어떤 노드까지의 경로는 반드시 존재한다.
트리는 루트노드 내부노드 리프노드로 이루어져 있다.
- 루트 노드: 최상위에 있는 노드를 의미한다.
- 내부 노드: 루트 노드와 리프 노드 사이, 또는 루트 노드와 내부 노드 사이에 있는 노드를 의미한다.
- 리프 노드: 자식 노드가 없는 노드를 의미한다.
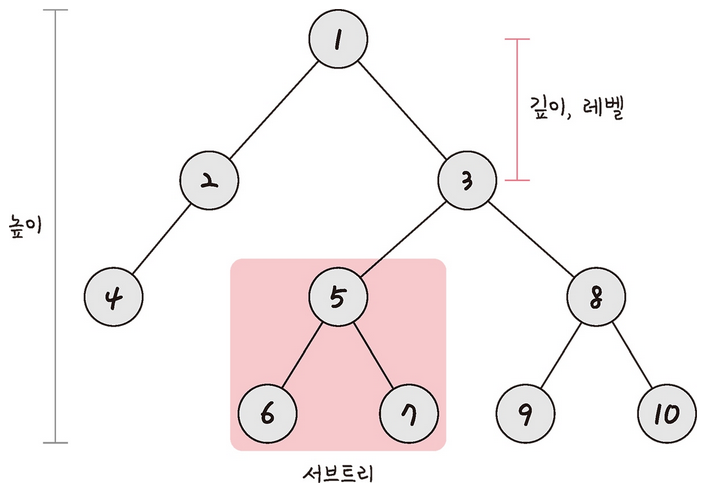
- 깊이: 트리에서의 깊이는 각 노드마다 다르며, 루트 노드부터 특정 노드까지 최단 거리로 갔을 때의 거리를 말한다.
예를 들어, 4번 노드의 깊이는 2이다. - 높이: 트리의 높이는 루트 노드로부터 리프 노드까지 거리 중 가장 긴 거리를 의미한다(세모 덩어리라고 보면 쉬움).
예를 들어, 위 트리의 높이는 3이다. - 레벨: 트리의 레벨은 주어지는 문제마다 조금씩 다르지만 보통 깊이와 같은 의미를 지닌다.
- 서브 트리: 트리 내의 하위 집합을 서브 트리라고 한다. 트리 내에 있는 부분집합이라고도 보면 된다.
이진 트리
이진 트리는 자식의 노드 수가 두 개 이하인 트리를 의미하며, 이를 다음과 같이 분류한다.
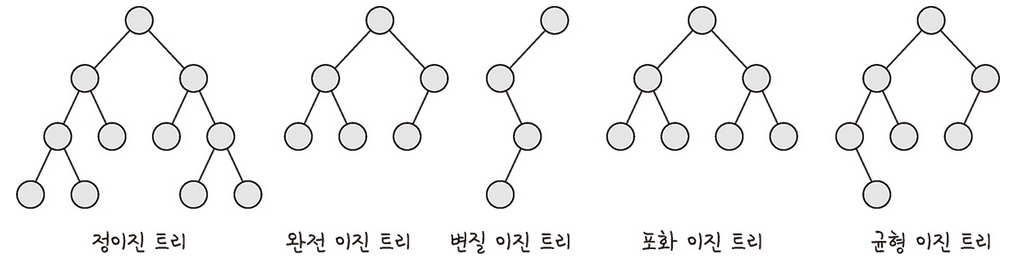
- 정 이진 트리(Full Binary Tree): 자식 노드가 0 또는 2개인 이진 트리를 의미한다.
- 완전 이진 트리(Complete Binary Tree): 왼쪽에서부터 채워져 있는 이진 트리를 의미한다. 마지막 레벨을 제외하고는 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 경우 왼쪽부터 채워져 있다.
- 변질 이진 트리(Degenerate Binary Tree): 자식 노드가 하나밖에 없는 이진 트리를 의미한다.
- 포화 이진 트리(Perfect Binary Tree): 모든 노드가 꽉 차있는 이진 트리를 의미힌다.
- 균형 이진 트리(Balanced Binary Tree): 왼쪽과 오른쪽 노드의 높이 차이가 1 이하인 이진 트리를 의미한다. map, set을 구성하는 레드 블랙 트리는 균형 이진 트리 중 하나다.
이진 탐색 트리
이진 탐색 트리(BST)는 노드의 오른쪽 하위 트리에는 '노드 값보다 큰 값'이, 왼쪽 하위 트리에는 '노드 값보다 작은 값'이
들어 있는 트리를 말한다.
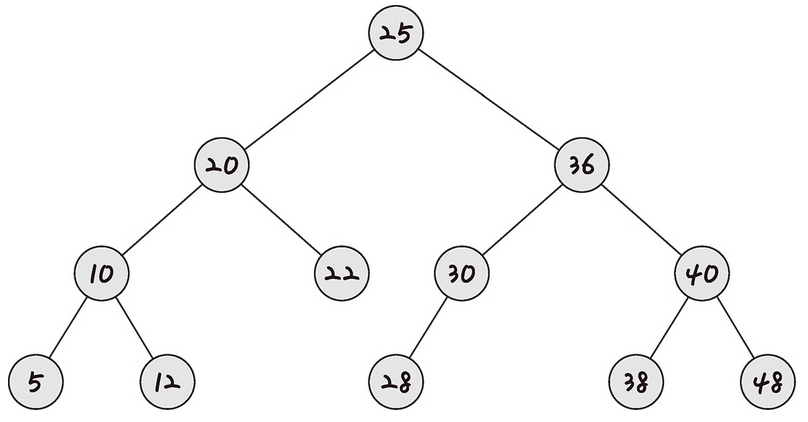
이를 사용하면 '검색'을 하기에 용이하다. 왼쪽에는 작은 값, 오른쪽에는 큰 값이 이미 정해져 있기 때문에 10을 찾으려고 한다면 25의 왼쪽 노드들만 찾으면 된다는 것은 자명하다. 보통 요소를 찾을 때 이진 탐색 트리의 경우 O(log n)이 걸린다. 하지만 최악의 경우 O(n)이 걸린다.
그 이유는 이진 탐색 트리는 삽입 순서에 따라 선형적일 수 있기 때문이다.
예시를 보면 바로 이해할 수 있다.
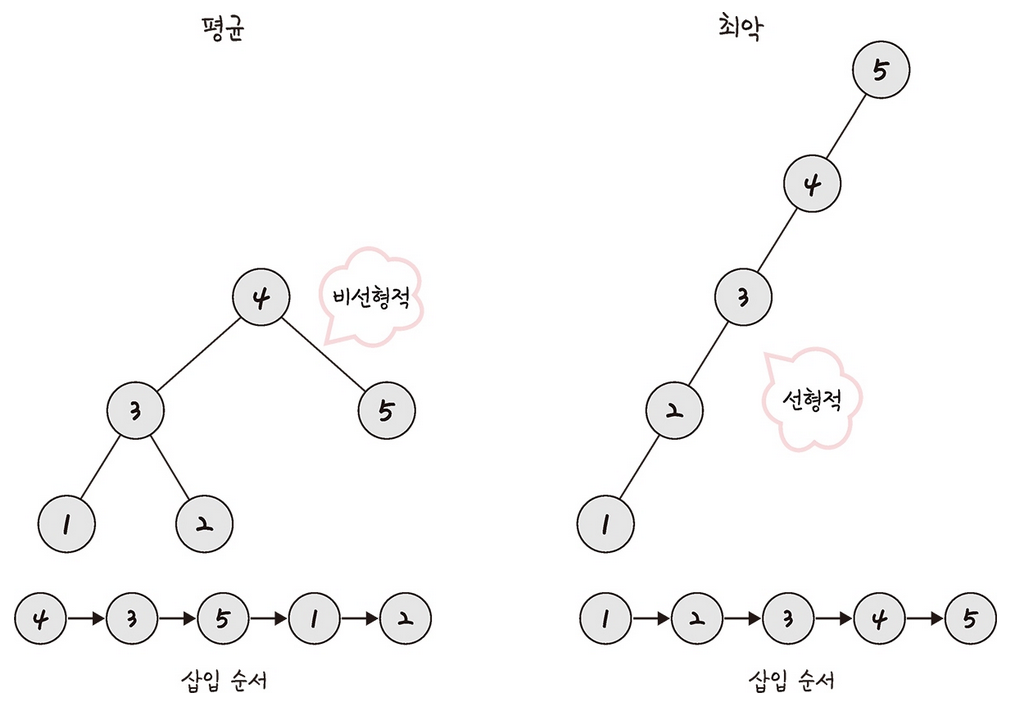
이진 탐색 트리(AVL 트리)
AVL 트리는 앞서 본 최악의 경우 선형적인 트리가 되는 것을 방지하고 스스로 균형을 잡는 이진 탐색 트리이다.
이진트리(Binary Tree)는 자식 노드가 최대 두 개인 노드들로 구성된 트리이고, 이진 탐색 트리(BST)는 이진 탐색과 연결 리스트를 결합한 자료구조이다. 이진 탐색의 효율적인 탐색 능력을 유지하면서, 빈번한 자료 입력과 삭제가 가능하다는 장점이 있다.
두 자식 서브 트리 높이는 항상 최대 1만큼 차이가 난다는 특징과 이진 트리와 같이 왼쪽 트리의 모든 값은 반드시 부모 노드보다 작아야 하고, 오른쪽 트리의 값은 부모 노드보다 커야 하는 특징이 있다.
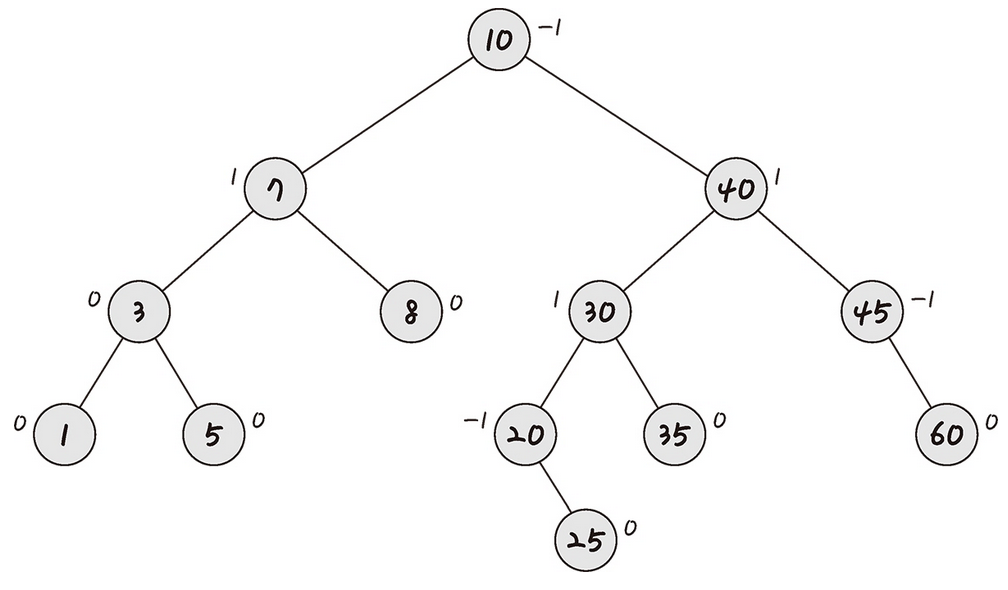
이진 탐색 트리는 선형적인 트리 형태를 가질 때 최악의 경우 O(n)의 시간 복잡도를 가진다. "이러한 최악의 경우를 배제하고 항상 균형잡힌 트리로 만들자." 라는 개념을 가진 트리가 바로 AVL 트리다.
탐색, 삽입, 삭제 모두 시간 복잡도가 O(log n)이며, 삽입, 삭제를 할 때마다 균형이 안 맞는 것을 맞추기 위해 트리 일부를 왼쪽 혹은 오른쪽으로 회전시키며 균형을 잡는다.
레드-블랙 트리(Red-Black Tree)
레드-블랙 트리는 이진 탐색 트리를 기반으로 하는 균형 이진 탐색 트리로 탐색, 삽입, 삭제 모두 시간 복잡도가 O(log n)이다.

각 노드는 빨간색 또는 검은 색의 색상을 나타내는 추가 비트를 저장하며, 삽입 및 삭제 중에 트리가 균형을 유지하도록 하는데 사용된다.
노드의 child가 없을 경우 child를 가리키는 포인터는 NIL 값을 저장한다. 이러한 NIL들을 leaf node로 간주한다. 모든 노드를 빨간색 또는 검은색으로 색칠하며, 연결된 노드들은 색이 중복되지 않는다.
"모든 리프 노드와 루트 노드는 블랙이고, 어떤 노드가 레드이면 그 노드의 자식은 반드시 블랙이다" 등의 규칙을 기반으로 균형을 잡는 트리이다.
레드 블랙 트리 삽입 과정)
https://www.youtube.com/watch?v=j0reRS7RUt8
5.3.3 힙
힙은 완전 이진 트리 기반의 자료구조이며, 최소힙과 최대힙 두 가지가 있고, 해당 힙에 따라 특정한 특징을 지킨 트리를 말한다.
- 최대힙: 루트 노드에 있는 키는 모든 자식에 있는 키 중에서 가장 커야 한다. 또한, 각 노드의 자식 노드와의 관계에도 이와 같은 특징이 재귀적으로 이루어져야 한다.
- 최소힙: 최소 힙에서 루트 노드에 있는 키는 모든 자식에 있는 키 중에서 최솟값이어야 한다. 또한, 각 노드의 자식 노드와의 관계도 이와 같은 특징이 재귀적으로 이루어져야 한다.
힙에는 어떠한 값이 들어와도 특정 힙의 규칙을 지키게 만들어져 있다. 예를 들어 최대 힙을 기반으로 설명하면 다음과 같다.
힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 이어서 삽입한다. 그런 다음, 이 새로운 노드를 부모 노드들과의 크기를 비교하며 교환해서 힙의 성질을 만족시킨다.
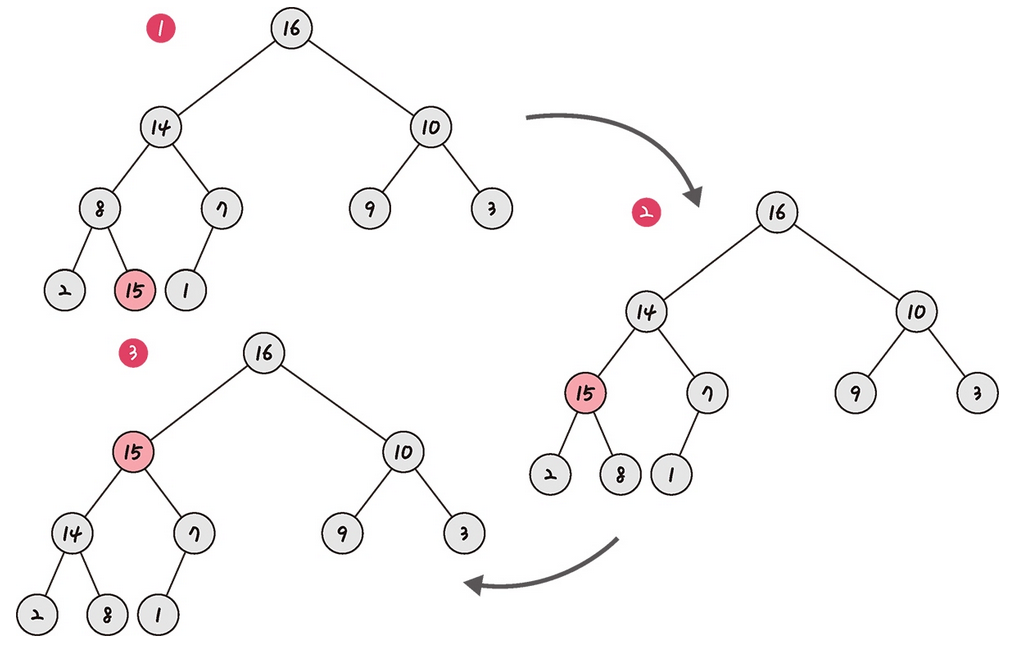
예를 들어 8이라는 값을 가진 노드 밑에 15라는 값을 가진 노드를 삽입하면 이 노드가 점차 올라가면서 해당 노드와 스왑하는 과정을 거쳐 최대힙 조건을 만족한다.
최대힙에서의 삭제 과정은 다음과 같다.
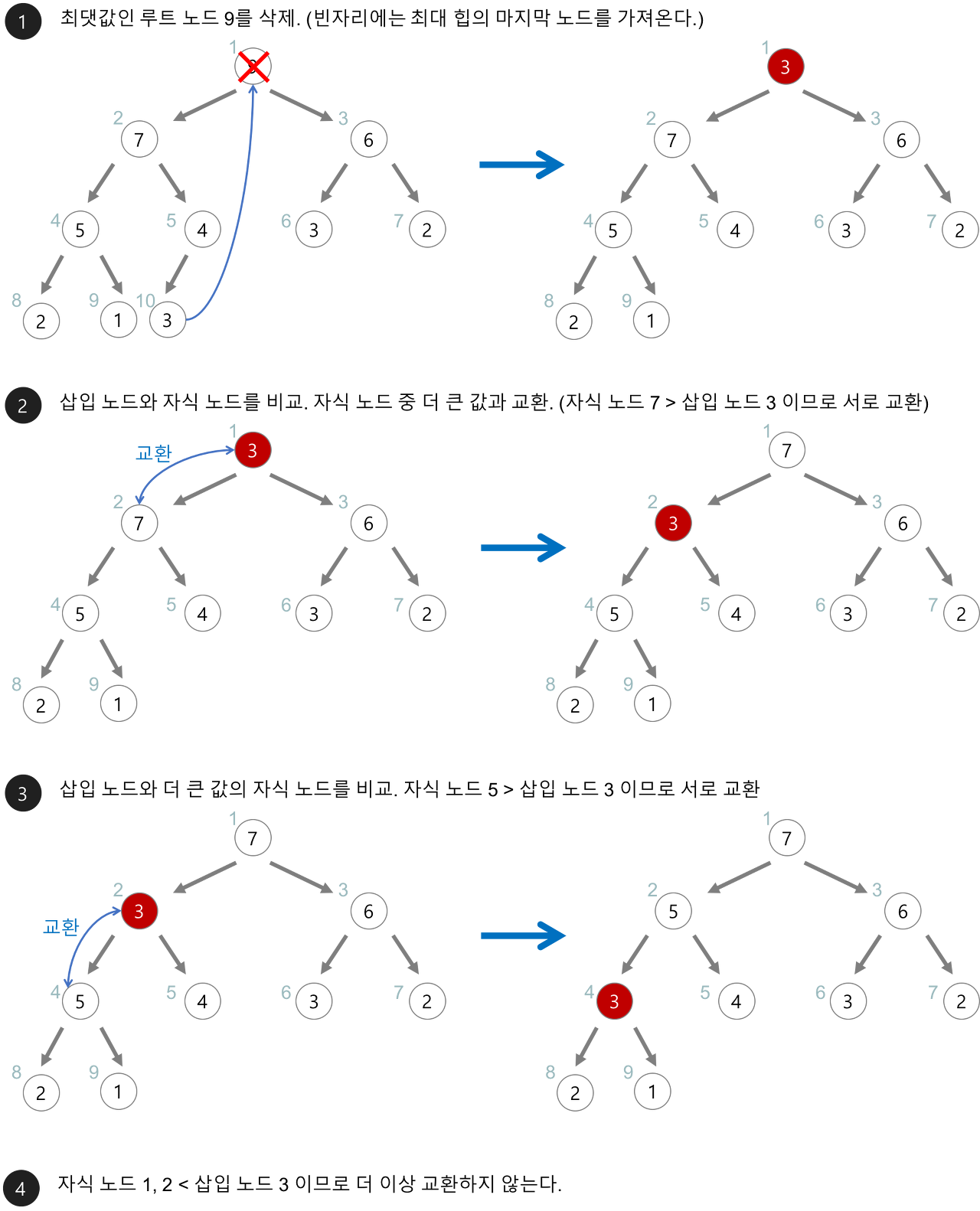
최대힙에서 최댓값은 루트노드이므로 루트 노드가 삭제되고, 그 이후 마지막 노드와 루트 노드를 스왑하여 또 다시 스왑 등의 과정을 거쳐 재구성된다.
GitHub - trekhleb/javascript-algorithms: 📝 Algorithms and data structures implemented in JavaScript with explanations and lin
📝 Algorithms and data structures implemented in JavaScript with explanations and links to further readings - GitHub - trekhleb/javascript-algorithms: 📝 Algorithms and data structures implemented in...
github.com
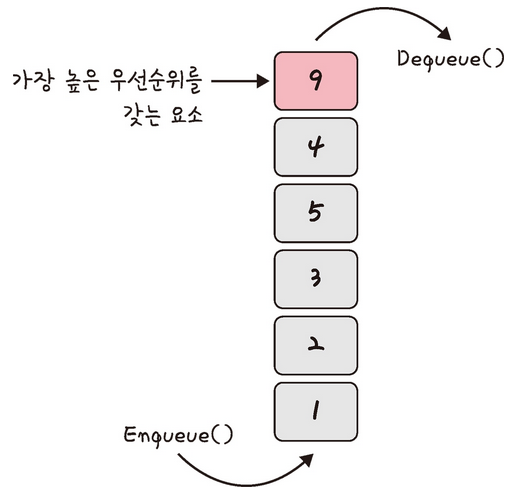
5.3.4 우선순위 큐(Priority Queue)
우선순위 큐는 들어간 순서에 상관없이 우선순위가 높은 데이터를 먼저 꺼내기 위해 고안된 자료구조이다.
우선순위 큐 구현 방식에는 배열, 연결 리스트, 힙이 있고, 그 중 힙 방식이 worst case라도 시간 복잡도 O(logN)을 보장하기 때문에 일반적으로 완전 이진트리 형태의 힙을 이용해 구현한다.
5.3.5 맵(Map)
맵은 특정 순서에 따라 키와 매핑된 값의 조합으로 형성된 자료구조이다. 레드 블랙 트리 자료 구조를 기반으로 형성되고 삽입하면 자동으로 정렬된다.
예를 들어 "가나다 : 1, "마바사" : 2" 같은 방식으로 값을 할당해야 할 때 쓴다.
5.3.6 셋(Set)
셋은 특정 순서에 따라 고유한 요소를 저장하는 컨테이너이며, 중복되는 요소는 없고 오로지 희소한 값만 저장하는 자료구조이다.
5.3.7 해시 테이블(Hash Table)
해시 테이블은 무한에 가까운 데이터들을 유한한 개수의 해시 값으로 매핑한 테이블이다. (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다.
빠른 검색 속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다.
각 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로 평균 O(1)의 시간 복잡도로 데이터를 조회한다. 하지만 index값이 충돌이 발생한 경우 Chanining에 연결된 리스트들까지 검색해야 하므로 O(N)까지 증가할 수 있다.
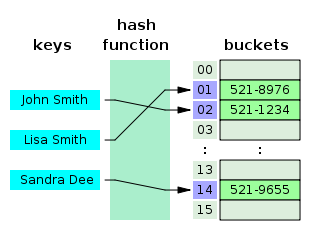
자바스크립트에서 해시테이블은 Map, Object, Set이 있다. 본래 자바스크립트에서 해시테이블 자료구조는 Object가 대표적이었으나, ES6에서 Map과 Set이 추가되었다고 한다. 그 중,Map은 대표적으로 해시맵이라고도 불린다.
해시 맵 with 자바스크립트)
[자료구조] 해시테이블(HashTable), 해시맵(HashMap) in Javascript
해시테이블(HashTable) 해시 테이블은 key-value pair로 데이터를 저장하는 자료구조 중 하나로, 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시테이블(Hash Table)의 구조 해시테이블에 대해 이해하
velog.io
'CS > 면접을 위한 CS 전공노트' 카테고리의 다른 글
| [회고] 뒤늦게 올리는 면접을 위한 CS 전공지식 노트 1회독 회고 (2) | 2023.05.17 |
|---|---|
| [데이터베이스] 트랜잭션과 무결성/인덱스/조인 (1) | 2023.05.02 |
| [데이터베이스] 데이터베이스 기본/ERD와 정규화 과정 (0) | 2023.04.29 |
| [운영체제] 공유자원과 임계영역/교착상태/CPU 스케줄링 알고리즘 (0) | 2023.04.24 |
| [운영체제] 프로세스와 스레드/ 멀티프로세싱과 멀티스레딩 (0) | 2023.04.22 |
